Guilherme Fernandes Secco
Data ScientistMachine Learning
Artificial Intelligence
About Me
🎓 Software Engineering student focused on Data Science and Artificial Intelligence, with strong emphasis on machine learning for real-world decision-making and risk analysis problems.
I have hands-on experience building end-to-end data science solutions, from data extraction and exploratory analysis to feature engineering, model training, evaluation, and deployment.
My main interests include predictive modeling, risk analysis, and automation, using tools such as Python, SQL, XGBoost, and data visualization platforms to support data-driven decisions.
I approach data science as a complete pipeline, ensuring that models are not only accurate, but also interpretable, reproducible, and aligned with business objectives.
💡 Goal
My goal is to become a full-fledged Data Scientist, I'm always looking for new challenges and new technologies to learn and master.
I constantly aim to combine statistics, programming, and software engineering to solve
problems efficiently.
🔧 Key Skills
- Python (Pandas, NumPy, Scikit-learn, XGBoost, Selenium, BeautifulSoup);
- Databases (PostgreSQL, MySQL, MongoDB);
- Machine Learning (Modeling, Preprocessing, Metrics, Explainability);
- Generative AI & LLMs (Prompt Engineering, Whisper, Gemini API, LangChain);
- Business Intelligence (Power BI, Excel, Power Query);
- Version Control & Collaboration (Git and GitHub);
- Agile Methodologies (Scrum and Kanban).
- Languages: Portuguese (Native), English - C1 (Cambridge English: First, Score 180).
🚀 Featured Projects
-
Credit Approval Simulator
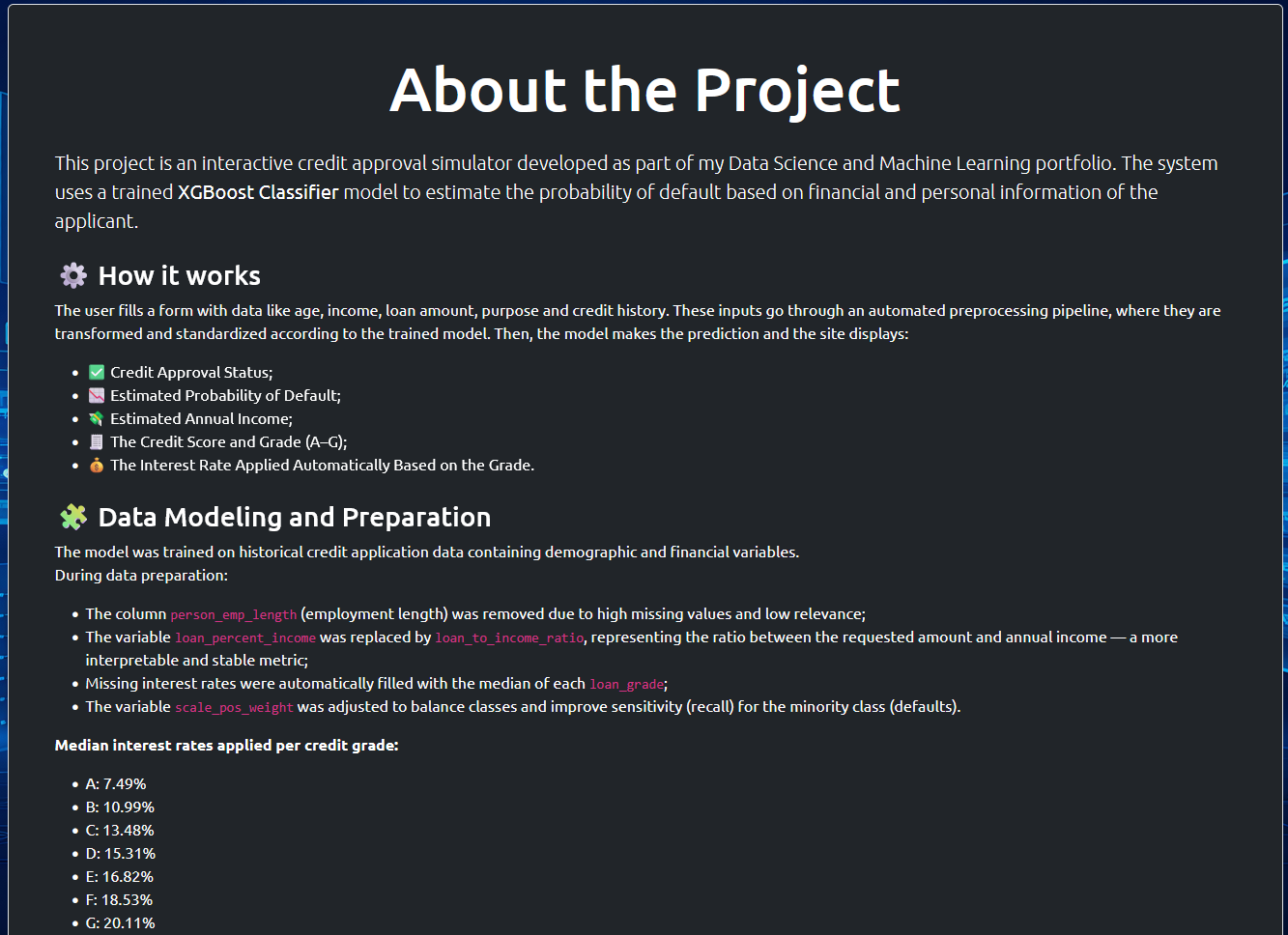 : An interactive credit approval simulator, it uses a XGBoostClassifier model to predict default risk and set personalized rates;
: An interactive credit approval simulator, it uses a XGBoostClassifier model to predict default risk and set personalized rates;
-
Olist Data Analysis
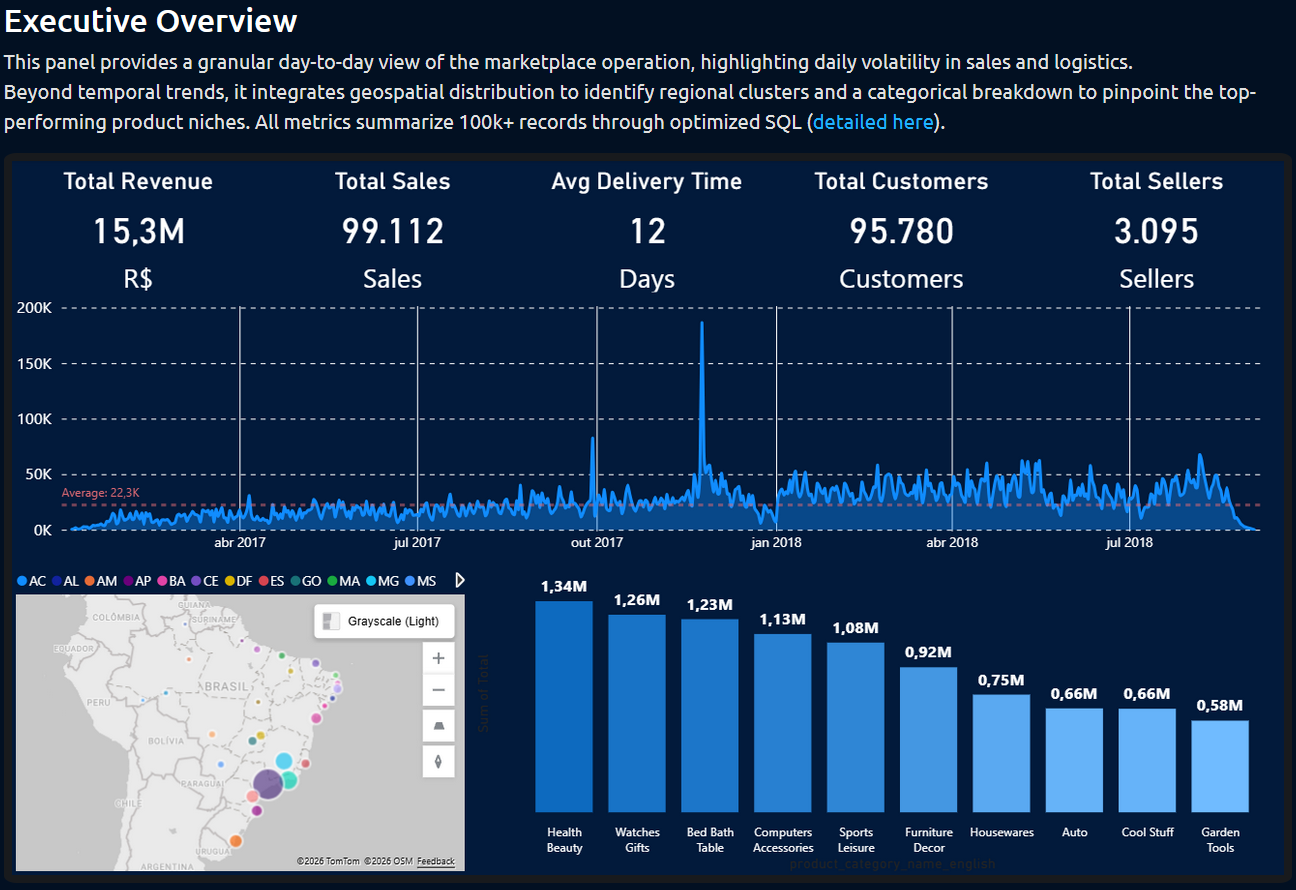 : A comprehensive data analysis project using PostgreSQL and Power BI to extract business insights from a large e-commerce dataset;
: A comprehensive data analysis project using PostgreSQL and Power BI to extract business insights from a large e-commerce dataset;
-
NLP Post Classifier
 : Post classifier that uses NLP techniques and a trained model to categorize LinkedIn job posts prior collected by Selenium;
: Post classifier that uses NLP techniques and a trained model to categorize LinkedIn job posts prior collected by Selenium;
-
YouTube LLM Summarizer
 : A complete pipeline that downloads videos, transcribes audio with Whisper, and generates structured summaries using Gemini 2.0 Flash.
: A complete pipeline that downloads videos, transcribes audio with Whisper, and generates structured summaries using Gemini 2.0 Flash.
💬 Looking for an internship in Data Science and Machine Learning.

Data Scientist
I dedicate a significant part of my time to developing personal projects in the areas of Data Science and automation. My main focus is building useful tools and predictive models that can be used in real-world applications.
Information
-
Personal Info
Age: 26 years
Date of Birth: August 30, 1999 -
Location
City: Bauru
State: São Paulo
Country: Brazil
-
Languages
Portuguese: Native
English: Advanced -
Education
Degree: Software Engineering
Institution: Unicesumar
Expected Graduation: December 2026
Technical Expertise
Data & Analytics
Data Manipulation
Pandas & NumPy: Data cleaning, feature engineering, and numerical processing used across all predictive projects.
SQL Ecosystem
PostgreSQL, MySQL & MongoDB: Advanced relational modeling, query optimization with Window functions and CTEs, NoSQL integration for scalable data storage.
Business Intelligence
Power BI & Storytelling: KPI design, executive dashboards, and business-driven insights with the use of output data from predictive models and cleaned datasets.
Business Tools
Advanced Excel: Pivot tables and data modeling for quick ad-hoc analysis focusing in KPIs and financial reporting.
ML & Automation
Predictive Modeling
Scikit-learn, XGBoost & LightGBM: Implementation of Classification, Regression, and Clustering algorithms with high AUC/F1-Score metrics.
Recommendation Systems: Experience with KNN and similarity-based models.
Evaluation: Experience with cross-validation and model selection techniques.
NLP & LLMs
Natural Language Processing: Text classification, sentiment analysis, and summarization using modern LLM APIs integration for automated insights.
Web Scraping
Selenium & BeautifulSoup: Automated extraction of unstructured data from complex web environments, essential for building custom datasets.
Development
Exploration & Deployment
Jupyter & Google Colab: Interactive environments for prototyping, EDA, and statistical experimentation.
Flask & Streamlit: Deploying model logic through APIs and interactive data tools.
Software Engineering
Git/GitHub: Version control with branching and organized documentation.
UV: High-speed Python package and environment management.
WSL2: Windows Subsystem for Linux for seamless integration with Linux-based tools and development environments.
Agile: Delivery-oriented mindset using Scrum/Kanban frameworks.
Professional Skills
English: C1 (Cambridge English: First, Score 180)
Soft Skills: High Learning Ability • Proactivity • Results Oriented • Teamwork.